原创连载|Apache Dubbo 漏洞分析—Apache Dubbo 编解码原理详解
原创连载|Apache Dubbo 漏洞分析—Apache Dubbo 编解码原理详解
01 Dubbo协议详解
首先,这里对Dubbo协议需要了解的知识进行一个简单介绍。对Dubbo协议详解具体可以看《深入理解Apache Dubbo与实战》书籍。
一次RPC调用包括协议头和协议体两部分。16字节长的报文头部主要携带了魔法数(0xdabb),以及当前请求报文是否是Request、Response心跳和事件的信息,请求时也会携带当前报文体内序列化协议编号。除此之外,报文头部还携带了请求状态,以及请求唯一标识和报文体长度。
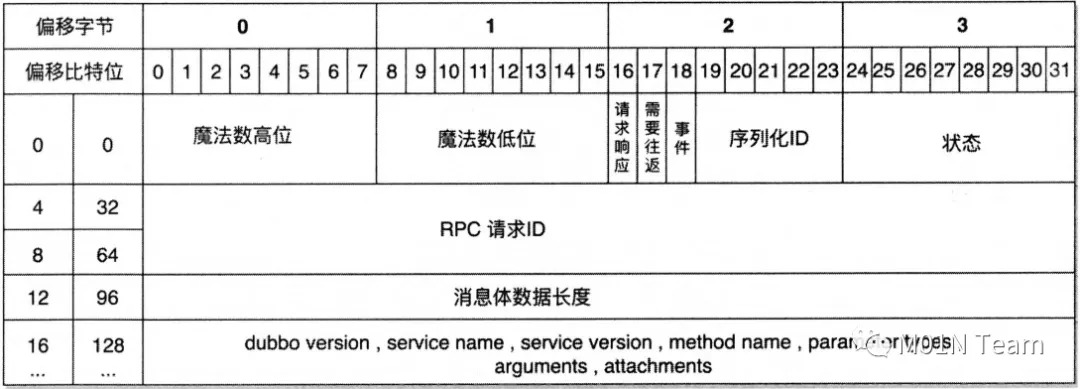
Dubbo具体字段代表意义
偏移比特位 | 字段描述 | 作 用 |
0~7 | 魔术高位 | 存储的是魔法数高位(0xda00) |
8~15 | 魔术低位 | 存储的是魔法数高位(0xbb) |
| 16 | 数据包类型 | 是否为双向的RPC调用(比如方法调用有返回值),0为Response, 1 为Request |
| 17 | 调用方式 | 仅在第16位被设为1的情况下有效0为单向调用,1为双向调用比如在优雅停机时服务端发送readonly不需要双向调用,这里标志位就不会设定 |
| 18 | 事件标识 | 0为当前数据包是请求或响应包1为当前数据包是心跳包,比如框架为了保活TCP连接,每次客户端和服务端互相发送心跳包时这个标志位被设定设置了心跳报文不会透传到业务方法调用,仅用于框架内部保活机制 |
19〜23 | 序列化器编 | 2 为 Hessian2Serialization 3 为 JavaSerialization 4 为 CompactedJavaSerialization 6 为 FastJsonSerialization 7 为 NativeJavaSerialization 8 为 KryoSerialization 9 为 FstSerialization |
24~31 | 状态 | 20 为 OK 30 为 CLIENT TIMEOUT 31 为 SERVER_TIMEOUT 40 为 BAD_REQUEST 50 为 BAD RESPONSE |
32~95 | 请求编号 | 这8个字节存储RPC请求的唯一 id,用来将请求和响应做关联 |
96~127 | 消息体长度 | 占用的4个字节存储消息体长度。在一次RPC请求过程中,消息体中依次会存储7部分内容 |
在消息体中,客户端严格按照序列化顺序写入消息,服务端也会遵循相同的顺序读取消息, 客户端发起请求的消息体依次保存下列内容:Dubbo版本号、服务接口名、服务接口版本、方法名、参数类型、方法参数值和请求额外参数(attachment)。
02 编解码器原理
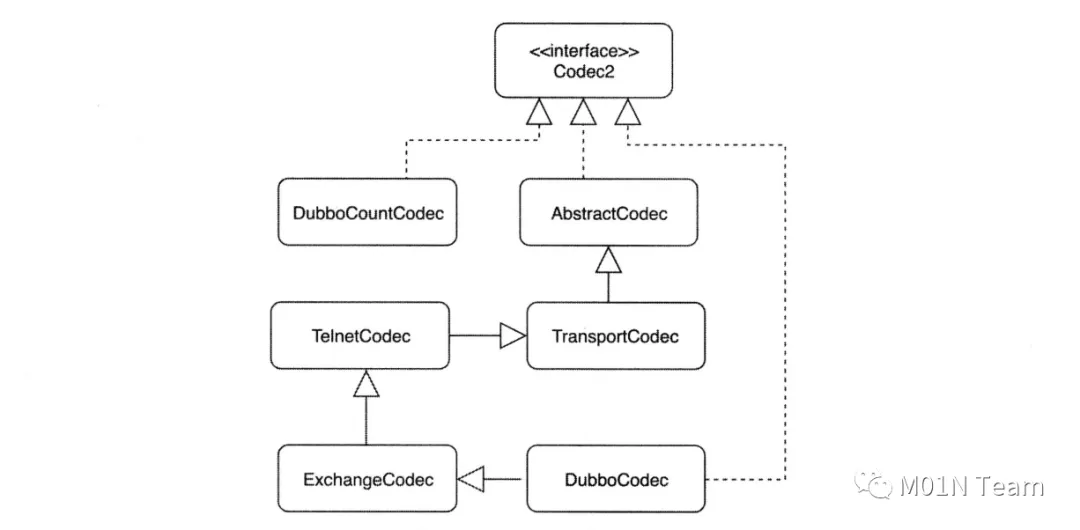
AbstractCodec主要提供基础能力,比如校验报文长度和查找具体编解码器等。TransportCodec主要抽象编解码实现,自动帮我们去调用序列化、反序列实现和自动cleanup流。
Dubbo协议编码器
Dubbo中的编码器主要将Java对象编码成字节流返回给客户端,主要做两部分事情,构造报文头部,然后对消息体进行序列化处理。所有编解码层实现都应该继承自Exchangecodec,Dubbo协议编码器也不例外。当Dubbo协议编码请求对象时,会调用ExchangeCodec#encode方法。我们首先分析编码请求对象,
org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encodeRequest
1protected void encodeRequest(Channel channel, ChannelBuffer buffer, Request req) throws IOException {
2 //1.获取指定或默认的序列化协议(Hessian2)
3 Serialization serialization = getSerialization(channel, req);
4 // header.2.构造 16 字节头
5 byte[] header = new byte[HEADER_LENGTH];
6 // set magic number. 3.占用 2 个字节存储魔法数
7 Bytes.short2bytes(MAGIC, header);
8
9 // set request and serialization flag.
10 //4. 在第3个字节(16位和19〜23位)分别存储请求标志和序列化协议序号
11 header[2] = (byte) (FLAG_REQUEST | serialization.getContentTypeId());
12
13 //5.设置请求/响应标记
14 if (req.isTwoWay()) {
15 header[2] |= FLAG_TWOWAY;
16 }
17 if (req.isEvent()) {
18 header[2] |= FLAG_EVENT;
19 }
20
21 // set request id.
22 //6.设置请求唯一标识
23 Bytes.long2bytes(req.getId(), header, 4);
24
25 // encode request data.
26 int savedWriteIndex = buffer.writerIndex();
27 //7.跳过buffer头部16个字节, 用于序列化消息体
28 buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
29 ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
30
31 if (req.isHeartbeat()) {
32 // heartbeat request data is always null
33 bos.write(CodecSupport.getNullBytesOf(serialization));
34 } else {
35 ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
36 if (req.isEvent()) {
37 encodeEventData(channel, out, req.getData());
38 } else {
39 //8. 序列化请求调用,data —般是Rpclnvocation
40 encodeRequestData(channel, out, req.getData(), req.getVersion());
41 }
42 out.flushBuffer();
43 if (out instanceof Cleanable) {
44 ((Cleanable) out).cleanup();
45 }
46 }
47
48 bos.flush();
49 bos.close();
50 int len = bos.writtenBytes();
51 //9.查是否超过默认8MB大小
52 checkPayload(channel, len);
53 //10.向消息长度写入头部第队个字节的偏移量(96~127位)
54 Bytes.int2bytes(len, header, 12);
55
56 // write
57 //11. 定位指针到报文头部开始位置
58 buffer.writerIndex(savedWriteIndex);
59 //12. 写入完整报文头部到buff
60 buffer.writeBytes(header); // write header.
61 //13. 设置writerindex到消息体结束位置
62 buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
63}这段代码的主要职责是将Dubbo请求对象编码成字节流(包括协议报文头部)。
1.提取URL中配置的序列化协议或默认协议。
2.创建16字节的报文头部。
3.首先会将魔法数写入头部并占用2个字节。
4.设置请求标识和消息体中使用的序列化协议。
5.会复用同一个字节,标记这个请求需要服务端返回。
6.承载请求的唯一标识,这个标识用于匹配响应的数据。
7.会在buffer中预留16字节存储头部
8.序列化请求部分,比如方法名等信息。
9.检查编码后的报文是否超过大小限制(默认是8MB)。
10.将消息体长度写入头部偏移量(第12个字节),长度占用4个字节。
11.将buffer定位到报文头部开始
12.将构造好的头部写入buffer。
13.将buffer写入索引执行消息体结尾的下一个位置。
通过上面的请求编码器实现,在理解协议的基础上很容易理解这里的代码,在8中会调用encodeRequestData方法对Rpclnvocation调用进行编码,这部分主要就是对接口、方法、 方法参数类型、方法参数等进行编码,在DubboCodec#encodeRequestData中重写了这个方法实现。
org.apache.dubbo.rpc.protocol.dubbo.DubboCodec#encodeRequestData
1@Override
2protected void encodeRequestData(Channel channel, ObjectOutput out, Object data, String version) throws IOException {
3 RpcInvocation inv = (RpcInvocation) data;
4
5 //1.写入框架版本
6 out.writeUTF(version);
7 // https://github.com/apache/dubbo/issues/6138
8 //2. 写入调用接口
9 String serviceName = inv.getAttachment(INTERFACE_KEY);
10 if (serviceName == null) {
11 serviceName = inv.getAttachment(PATH_KEY);
12 }
13 //3. 写入接口名称与接口的指定版本,默认为0.0.0
14 out.writeUTF(serviceName);
15 out.writeUTF(inv.getAttachment(VERSION_KEY));
16 //4. 写入方法名称
17 out.writeUTF(inv.getMethodName());
18 //5. 写入方法参数类型
19 out.writeUTF(inv.getParameterTypesDesc());
20 Object[] args = inv.getArguments();
21 if (args != null) {//6.依次写入方法参数值
22 for (int i = 0; i args.length; i++) {
23 out.writeObject(encodeInvocationArgument(channel, inv, i));
24 }
25 }//7.写入请求额外参数
26 out.writeAttachments(inv.getObjectAttachments());
27}这段代码的主要职责是将Dubbo方法调用参数和值编码成字节流。在编码消息体的时候:
先写入框架的版本,这里主要用于支持服务端版本隔离和服务端请求额外参数透传给客户端的特性。
向服务端写入调用的接口。
指定接口的版本,默认版本为0.0.0,Dubbo允许同一个接口有多个实现,可以指定版本或分组来区分。
指定远程调用的接口方法。
将方法参数类型以Java类型方式传递给服务端。
循环对参数值进行序列化。
写入请求额外参数HashMap,这里可能包含timeout和group等动态参数。
在处理完编码请求后,我们继续分析编码响应对象,理解了编码请求对象后,比较好理解响应,响应实现在ExchangeCodec#encodeResponse中。
org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encodeResponse
1protected void encodeResponse(Channel channel, ChannelBuffer buffer, Response res) throws IOException {
2 int savedWriteIndex = buffer.writerIndex();
3 try {
4 //1.获取指定或默认的序列化协议(Hessian2 )
5 Serialization serialization = getSerialization(channel, res);
6 // header.
7 //2.构造 16 字节头
8 byte[] header = new byte[HEADER_LENGTH];
9 // set magic number.
10 //3.占用2个字节存储魔法数
11 Bytes.short2bytes(MAGIC, header);
12 // set request and serialization flag.
13 //4.在第3个字节(19〜23位)存储响应标志
14 header[2] = serialization.getContentTypeId();
15 if (res.isHeartbeat()) {
16 header[2] |= FLAG_EVENT;
17 }
18 // set response status.
19 //5.在第4个字节存储响应状态
20 byte status = res.getStatus();
21 header[3] = status;
22 // set request id.
23 //6.设置请求唯一标识
24 Bytes.long2bytes(res.getId(), header, 4);
25 //7.空出16字节头部用于存储响应体报文
26 buffer.writerIndex(savedWriteIndex + HEADER_LENGTH);
27 ChannelBufferOutputStream bos = new ChannelBufferOutputStream(buffer);
28
29 // encode response data or error message.
30 if (status == Response.OK) {
31 if(res.isHeartbeat()){
32 // heartbeat response data is always null
33 bos.write(CodecSupport.getNullBytesOf(serialization));
34 }else {
35 ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
36 if (res.isEvent()) {
37 encodeEventData(channel, out, res.getResult());
38 } else {
39 //8.序列化响应调用,data-般是 Result对象
40 encodeResponseData(channel, out, res.getResult(), res.getVersion());
41 }
42 out.flushBuffer();
43 if (out instanceof Cleanable) {
44 ((Cleanable) out).cleanup();
45 }
46 }
47 } else {
48 ObjectOutput out = serialization.serialize(channel.getUrl(), bos);
49 out.writeUTF(res.getErrorMessage());
50 out.flushBuffer();
51 if (out instanceof Cleanable) {
52 ((Cleanable) out).cleanup();
53 }
54 }
55
56 bos.flush();
57 bos.close();
58 //9.检查是否超过默认的8MB大小
59 int len = bos.writtenBytes();
60 checkPayload(channel, len);
61 //10.向消息长度写入头部第12个字节偏移量(96 ~ 127 位)
62 Bytes.int2bytes(len, header, 12);
63 // write
64 //11.定位指针到报文头部开始位置
65 buffer.writerIndex(savedWriteIndex);
66 //12.写入完整报文头部到 buffer
67 buffer.writeBytes(header); // write header.
68 //13.设置writerindex到消息体结束位置|
69 buffer.writerIndex(savedWriteIndex + HEADER_LENGTH + len);
70 } catch (Throwable t) {
71 // clear buffer
72 //14.如果编码失败,则复位 buffer
73 buffer.writerIndex(savedWriteIndex);
74 // send error message to Consumer, otherwise, Consumer will wait till timeout.
75 //15.将编码响应异常发送给consumer,否则只能等待到超时
76 if (!res.isEvent()
78 r.setStatus(Response.BAD_RESPONSE);
79
80 if (t instanceof ExceedPayloadLimitException) {
81 logger.warn(t.getMessage(), t);
82 try {
83 r.setErrorMessage(t.getMessage());
84 //16.告知客户端数据包长度超过限制
85 channel.send(r);
86 return;
87 } catch (RemotingException e) {
88 logger.warn("Failed to send bad_response info back: " + t.getMessage() + ", cause: " + e.getMessage(), e);
89 }
90 } else {
91 // FIXME log error message in Codec and handle in caught() of IoHanndler?
92 logger.warn("Fail to encode response: " + res + ", send bad_response info instead, cause: " + t.getMessage(), t);
93 try {
94 //17.告知客户端编码失败的具体原因
95 r.setErrorMessage("Failed to send response: " + res + ", cause: " + StringUtils.toString(t));
96 channel.send(r);
97 return;
98 } catch (RemotingException e) {
99 logger.warn("Failed to send bad_response info back: " + res + ", cause: " + e.getMessage(), e);
100 }
101 }
102 }
103
104 // Rethrow exception
105 if (t instanceof IOException) {
106 throw (IOException) t;
107 } else if (t instanceof RuntimeException) {
108 throw (RuntimeException) t;
109 } else if (t instanceof Error) {
110 throw (Error) t;
111 } else {
112 throw new RuntimeException(t.getMessage(), t);
113 }
114 }
115}这段代码的主要职责是将Dubbo响应对象编码成字节流(包括协议报文头部)。在编码响应中:
1.获取用户指定或默认的序列化协议
2.构造报文头部(16字节)。
3.将魔法数填入报文头部前2个字节。
4.将服务端配置的序列化协议写入头部。
5.报文头部中status会保存服务端调用状态码。
6.将请求唯一id设置回响应头中。
7.空出16字节头部用于存储响应体报文。
8.对服务端调用结果进行编码,后面会进行详细解释。
9.对响应报文大小做检查,默认校验是否超过8MB大小。
10.将消息体长度写入头部偏移量(第12个字节),长度占用4个字节。
11.将buffer定位到报文头部开始,
12.将构造好的头部写入buffer。
13.将buffer写入索引执行消息体结尾的下一个位置
14.处理编码报错复位buffer,否则导致缓冲区中数据错乱。
15.将异常响应返回到客户端,防止客户端只有等到超时才能感知服务调用返回。
16.对报错进行了细分,处理服务端报文超过限制和具体报错原因。为了防止报错对象无法在客户端反序列化,在服务端会将异常信息转成字符串处理。
我们再回到编码响应消息提的部分,在8中处理响应,具体实现在DubboCodec#encodeResponseData中。
1@Override
2protected void encodeResponseData(Channel channel, ObjectOutput out, Object data, String version) throws IOException {
3 Result result = (Result) data;
4 //1.判断客户端请求的版本是否支持服务端参数返回 2.0.2≤version≤2.0.99
5 // currently, the version value in Response records the version of Request
6 boolean attach = Version.isSupportResponseAttachment(version);
7 Throwable th = result.getException();
8 if (th == null) {
9 //2. 提取正常返回结果
10 Object ret = result.getValue();
11 if (ret == null) {
12 //3. 在编码结果前,先写一个字节标志
13 out.writeByte(attach ? RESPONSE_NULL_VALUE_WITH_ATTACHMENTS : RESPONSE_NULL_VALUE);
14 } else {
15 out.writeByte(attach ? RESPONSE_VALUE_WITH_ATTACHMENTS : RESPONSE_VALUE);
16 //4.分别写一个字节标记和调用结果
17 out.writeObject(ret);
18 }
19 } else {
20 //5.标记调用抛异常,并序列化异常
21 out.writeByte(attach ? RESPONSE_WITH_EXCEPTION_WITH_ATTACHMENTS : RESPONSE_WITH_EXCEPTION);
22 out.writeThrowable(th);
23 }
24
25 if (attach) {
26 //6.记录服务端 Dubbo 版本,并返回服务端请求额外参数
27 // returns current version of Response to consumer side.
28 result.getObjectAttachments().put(DUBBO_VERSION_KEY, Version.getProtocolVersion());
29 out.writeAttachments(result.getObjectAttachments());
30 }
31}这段代码的主要职责是将Dubbo方法调用状态和返回值编码成字节流。编码响应体也是比较简单的:
1.判断客户端的版本是否支持请求额外参数从服务端传递到客户端。
2.处理正常服务调用,并且返回值为null的场景,用一个字节标记。
3.处理正常服务调用,并且返回值为null的场景,用一个字节标记。
4.处理方法正常调用并且有返回值,先写一个字节标记并序列化结果。
5.处理方法调用发生异常,写一个字节标记并序列化异常对象。
6.处理客户端支持请求额外参数回传,记录服务端Dubbo版本,并返回服务端请求额外参数。
除了编码请求和响应对象,还有一种处理普通字符串的场景,这种场景正是为了支持Telnet协议调用实现的,这里主要是简单读取字符串值处理,后面会继续分析。
Dubbo协议解码器
相比较编码而言,解码要复杂一些。解码工作分为2部分,第1部分解码报文的头部(16字节),第2部分解码报文体内容,以及如何把报文体转换成Rpclnvocation 。当服务端读取流进行解码时,会触发ExchangeCodec#decode方法,Dubbo协议解码继承了这个类实现,但是在解析消息体时,Dubbo协议重写了decodeBody方法。我们先分析解码头部的部分。
org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#decode
1@Override
2public Object decode(Channel channel, ChannelBuffer buffer) throws IOException {
3 int readable = buffer.readableBytes();
4 //1.最多读取16个字节,并分配存储空间
5 byte[] header = new byte[Math.min(readable, HEADER_LENGTH)];
6 buffer.readBytes(header);
7 return decode(channel, buffer, readable, header);
8}
9
10@Override
11protected Object decode(Channel channel, ChannelBuffer buffer, int readable, byte[] header) throws IOException {
12 // check magic number.
13 //2.处理流起始处不是Dubbo魔法数0xdabb场景
14 if (readable > 0
17 //3.流中还有数据可以读取
18 if (header.length readable) {
19 //4.为 header 重新分配空间,用来存储流中所有可读字节
20 header = Bytes.copyOf(header, readable);
21 //5.将流中剩余字节读取到header中
22 buffer.readBytes(header, length, readable - length);
23 }
24 for (int i = 1; i header.length - 1; i++) {
25 if (header[i] == MAGIC_HIGH
28 //7.将流起始处至下一个Dubbo报文之间的数据放到header中
29 header = Bytes.copyOf(header, i);
30 break;
31 }
32 }
33 //8.主要用于解析header数据,比如用于Telnet
34 return super.decode(channel, buffer, readable, header);
35 }
36 // check length.
37 //9.如果读取数据长度小于16个字节,则期待更多数据
38 if (readable HEADER_LENGTH) {
39 return DecodeResult.NEED_MORE_INPUT;
40 }
41
42 // get data length.
43 //10.提取头部存储的报文长度,并校验长度是否超过限制
44 int len = Bytes.bytes2int(header, 12);
45
46 // When receiving response, how to exceed the length, then directly construct a response to the client.
47 // see more detail from https://github.com/apache/dubbo/issues/7021.
48 Object obj = finishRespWhenOverPayload(channel, len, header);
49 if (null != obj) {
50 return obj;
51 }
52
53 checkPayload(channel, len);
54
55 int tt = len + HEADER_LENGTH;
56 //11.校验是否可以读取完整Dubbo报文,否则期待更多数据
57 if (readable tt) {
58 return DecodeResult.NEED_MORE_INPUT;
59 }
60
61 // limit input stream.
62 ChannelBufferInputStream is = new ChannelBufferInputStream(buffer, len);
63
64 try {
65 //12.解码消息体,is流是完整的 RPC 调用报文
66 return decodeBody(channel, is, header);
67 } finally {
68 //13.如果解码过程有问题,则跳过这次RPC调用报文
69 if (is.available() > 0) {
70 try {
71 if (logger.isWarnEnabled()) {
72 logger.warn("Skip input stream " + is.available());
73 }
74 StreamUtils.skipUnusedStream(is);
75 } catch (IOException e) {
76 logger.warn(e.getMessage(), e);
77 }
78 }
79 }
80}整体实现解码过程中要解决粘包和半包问题。
最多读取Dubbo报文头部(16字节), 如果流中不足16字节,则会把流中数据读取完毕。在decode方法中会先判断流当前位置是不是Dubbo报文开始处,在流中判断报文分割点是通过2判断的(0xdabb魔法数)。如果当前流中没有遇到完整Dubbo报文(在3中会判断流可读字节数),在4中会为剩余可读流分配存储空间,在5中会将流中数据全部读取并追加在header数组中。当流被读取完后,会查找流中第一个Dubbo报文开始处的索引,在6中会将buffer索引指向流中第一个Dubbo报文开始处(0xdabb)。在7中主要将流中从起始位置(初始buffer的readerindex)到第一个Dubbo报文开始处的数据保存在header中,用于9解码header数据,目前常用的场景有Telnet调用等。
在正常场景中解析时,在10中首先判断当次读取的字节是否多于16字节,否则等待更多网络数据到来。在10中会判断Dubbo报文头部包含的消息体长度,然后校验消息体长度是否超过限制(默认为8MB 。在11中会校验这次解码能否处理整个报文。在12中处理消息体解码,这个是强协议相关的,因此Dubbo协议重写了这部分实现,我们先看一下在DubboCodec#decodeBody中是如何处理的。
org.apache.dubbo.rpc.protocol.dubbo.DubboCodec#decodeBody
1@Override
2protected Object decodeBody(Channel channel, InputStream is, byte[] header) throws IOException {
3 byte flag = header[2], proto = (byte) (flag
4 // get request id.
5 long id = Bytes.bytes2long(header, 4);
6 if ((flag
9 if ((flag
11 }
12 // get status.
13 byte status = header[3];
14 res.setStatus(status);
15 try {
16 if (status == Response.OK) {
17 Object data;
18 if (res.isEvent()) {
19 byte[] eventPayload = CodecSupport.getPayload(is);
20 if (CodecSupport.isHeartBeat(eventPayload, proto)) {
21 // heart beat response data is always null;
22 data = null;
23 } else {
24 ObjectInput in = CodecSupport.deserialize(channel.getUrl(), new ByteArrayInputStream(eventPayload), proto);
25 data = decodeEventData(channel, in, eventPayload);
26 }
27 } else {
28 DecodeableRpcResult result;
29 if (channel.getUrl().getParameter(DECODE_IN_IO_THREAD_KEY, DEFAULT_DECODE_IN_IO_THREAD)) {
30 result = new DecodeableRpcResult(channel, res, is,
31 (Invocation) getRequestData(id), proto);
32 result.decode();
33 } else {
34 result = new DecodeableRpcResult(channel, res,
35 new UnsafeByteArrayInputStream(readMessageData(is)),
36 (Invocation) getRequestData(id), proto);
37 }
38 data = result;
39 }
40 res.setResult(data);
41 } else {
42 ObjectInput in = CodecSupport.deserialize(channel.getUrl(), is, proto);
43 res.setErrorMessage(in.readUTF());
44 }
45 } catch (Throwable t) {
46 if (log.isWarnEnabled()) {
47 log.warn("Decode response failed: " + t.getMessage(), t);
48 }
49 res.setStatus(Response.CLIENT_ERROR);
50 res.setErrorMessage(StringUtils.toString(t));
51 }
52 return res;
53 } else {
54 // decode request.
55 //1.请求标志位被设置,创建Request对象
56 Request req = new Request(id);
57 req.setVersion(Version.getProtocolVersion());
58 req.setTwoWay((flag
59 if ((flag
61 }
62 try {
63 Object data;
64 if (req.isEvent()) {
65 byte[] eventPayload = CodecSupport.getPayload(is);
66 if (CodecSupport.isHeartBeat(eventPayload, proto)) {
67 // heart beat response data is always null;
68 data = null;
69 } else {
70 ObjectInput in = CodecSupport.deserialize(channel.getUrl(), new ByteArrayInputStream(eventPayload), proto);
71 data = decodeEventData(channel, in, eventPayload);
72 }
73 } else {
74 DecodeableRpcInvocation inv;
75 if (channel.getUrl().getParameter(DECODE_IN_IO_THREAD_KEY, DEFAULT_DECODE_IN_IO_THREAD)) {
76 //2.在I/O线程中直接解码
77 inv = new DecodeableRpcInvocation(channel, req, is, proto);
78 inv.decode();
79 } else {
80 //3.交给Dubbo业务线程池解码
81 inv = new DecodeableRpcInvocation(channel, req,
82 new UnsafeByteArrayInputStream(readMessageData(is)), proto);
83 }
84 data = inv;
85 }
86 //4.将 Rpclnvocation 作为 Request 的数据域
87 req.setData(data);
88 } catch (Throwable t) {
89 if (log.isWarnEnabled()) {
90 log.warn("Decode request failed: " + t.getMessage(), t);
91 }
92 // bad request
93 //5.解码失败,先做标记并存储异常
94 req.setBroken(true);
95 req.setData(t);
96 }
97
98 return req;
99 }
100}org.apache.dubbo.remoting.transport.CodecSupport#deserialize
封装了输入流对象,并通过SPI选择对应的反序列化实现,在decode解码输入流时,对其数据进行反序列化:
1public static ObjectInput deserialize(URL url, InputStream is, byte proto) throws IOException {
2 Serialization s = getSerialization(url, proto);
3 return s.deserialize(url, is);
4}org.apache.dubbo.remoting.transport.CodecSupport#getSerialization
1 public static Serialization getSerialization(URL url, Byte id) throws IOException {
2 //获取对应的反序列化实现方法
3 Serialization result = getSerializationById(id);
4 if (result == null) {
5 throw new IOException("Unrecognized serialize type from consumer: " + id);
6 }
7 return result;
8 }org.apache.dubbo.remoting.transport.CodecSupport#getSerializationById
1 static {
2 SetString> supportedExtensions = ExtensionLoader.getExtensionLoader(Serialization.class).getSupportedExtensions();
3 for (String name : supportedExtensions) {
4 Serialization serialization = ExtensionLoader.getExtensionLoader(Serialization.class).getExtension(name);
5 byte idByte = serialization.getContentTypeId();
6 if (ID_SERIALIZATION_MAP.containsKey(idByte)) {
7 logger.error("Serialization extension " + serialization.getClass().getName()
8 + " has duplicate id to Serialization extension "
9 + ID_SERIALIZATION_MAP.get(idByte).getClass().getName()
10 + ", ignore this Serialization extension");
11 continue;
12 }
13 ID_SERIALIZATION_MAP.put(idByte, serialization);
14 ID_SERIALIZATIONNAME_MAP.put(idByte, name);
15 SERIALIZATIONNAME_ID_MAP.put(name, idByte);
16 }
17 }
18
19 public static Serialization getSerializationById(Byte id) {
20 return ID_SERIALIZATION_MAP.get(id);
21 }在调用CodecSupport的deserialize方法时,我们可以看到它传入的第三个参数proto,这是从dubbo协议数据包的header部获取的数据,在header的19-23位,表示Serialization编号,在获取反序列化实现时,根据这个编号从ID_SERIALIZATION_MAP缓存中取出相应的反序列化实现。
接下来,我们分析一下如何把消息体转换成Rpclnvocation对象,具体解码会触发DecodeableRpcInvocation#decode方法。
org.apache.dubbo.rpc.protocol.dubbo.DecodeableRpcInvocation#decode
1 @Override
2 public Object decode(Channel channel, InputStream input) throws IOException {
3 ObjectInput in = CodecSupport.getSerialization(channel.getUrl(), serializationType)
4 .deserialize(channel.getUrl(), input);
5 this.put(SERIALIZATION_ID_KEY, serializationType);
6
7 //1.
8 String dubboVersion = in.readUTF();
9 request.setVersion(dubboVersion);
10 setAttachment(DUBBO_VERSION_KEY, dubboVersion);
11
12 String path = in.readUTF();
13 //2.读取调用接口
14 setAttachment(PATH_KEY, path);
15 String version = in.readUTF();
16 //3.读取接口指定的版本,默认为0.0.0
17 setAttachment(VERSION_KEY, version);
18 //4.读取方法名称
19 setMethodName(in.readUTF());
20 //5.读取方法参数类型
21 String desc = in.readUTF();
22 setParameterTypesDesc(desc);
23
24 try {
25 if (ConfigurationUtils.getSystemConfiguration().getBoolean(SERIALIZATION_SECURITY_CHECK_KEY, true)) {
26 CodecSupport.checkSerialization(path, version, serializationType);
27 }
28 Object[] args = DubboCodec.EMPTY_OBJECT_ARRAY;
29 Class?>[] pts = DubboCodec.EMPTY_CLASS_ARRAY;
30 if (desc.length() > 0) {
31// if (RpcUtils.isGenericCall(path, getMethodName()) || RpcUtils.isEcho(path, getMethodName())) {
32// pts = ReflectUtils.desc2classArray(desc);
33// } else {
34 ServiceRepository repository = ApplicationModel.getServiceRepository();
35 ServiceDescriptor serviceDescriptor = repository.lookupService(path);
36 if (serviceDescriptor != null) {
37 MethodDescriptor methodDescriptor = serviceDescriptor.getMethod(getMethodName(), desc);
38 if (methodDescriptor != null) {
39 pts = methodDescriptor.getParameterClasses();
40 this.setReturnTypes(methodDescriptor.getReturnTypes());
41 }
42 }
43 if (pts == DubboCodec.EMPTY_CLASS_ARRAY) {
44 if (!RpcUtils.isGenericCall(desc, getMethodName())
46 }
47 pts = ReflectUtils.desc2classArray(desc);
48 }
49// }
50
51 args = new Object[pts.length];
52 for (int i = 0; i args.length; i++) {
53 try {
54 //6.依次读取方法参数值
55 args[i] = in.readObject(pts[i]);
56 } catch (Exception e) {
57 if (log.isWarnEnabled()) {
58 log.warn("Decode argument failed: " + e.getMessage(), e);
59 }
60 }
61 }
62 }
63 setParameterTypes(pts);
64 //7.读取请求额外参数
65 MapString, Object> map = in.readAttachments();
66 if (map != null String, Object> attachment = getObjectAttachments();
68 if (attachment == null) {
69 attachment = new LinkedHashMap>();
70 }
71 attachment.putAll(map);
72 setObjectAttachments(attachment);
73 }
74
75 //decode argument ,may be callback
76 //8.处理异步参数回调,如果有则在服务端创建 reference 代理实例
77 for (int i = 0; i args.length; i++) {
78 args[i] = decodeInvocationArgument(channel, this, pts, i, args[i]);
79 }
80
81 setArguments(args);
82 String targetServiceName = buildKey((String) getAttachment(PATH_KEY),
83 getAttachment(GROUP_KEY),
84 getAttachment(VERSION_KEY));
85 setTargetServiceUniqueName(targetServiceName);
86 } catch (ClassNotFoundException e) {
87 throw new IOException(StringUtils.toString("Read invocation data failed.", e));
88 } finally {
89 if (in instanceof Cleanable) {
90 ((Cleanable) in).cleanup();
91 }
92 }
93 return this;
94 }在解码请求时,是严格按照客户端写数据顺序来处理的。
1.读取远端传递的框架版本
2.读取调用接口全称
3.读取调用的服务版本,用来实现分组和版本隔离。
4.读取调用方法的名称
5.读取方法参数类型,通过类型能够解析出实际参数个数。
6.对方法参数值依次读取,这里具体解析参数值是和序列化协议相关的。
7.读取请求额外参数,比如同机房优先调用会读取其中的tag值。
8.为了支持异步参数回调,因为参数是回调客户端方法,所以需要在服务端创建客户端连接代理。
解码响应和解码请求类似,解码响应会调用DubboCodec#decodeBody方法,为了节省篇幅我们重点讲解解码响应的结果值。当方法调用返回时,会触发DecodeableRpcResult#decode方法调用。
org.apache.dubbo.rpc.protocol.dubbo.DecodeableRpcResult#decode
1 @Override
2 public Object decode(Channel channel, InputStream input) throws IOException {
3 if (log.isDebugEnabled()) {
4 Thread thread = Thread.currentThread();
5 log.debug("Decoding in thread -- [" + thread.getName() + "#" + thread.getId() + "]");
6 }
7
8 ObjectInput in = CodecSupport.getSerialization(channel.getUrl(), serializationType)
9 .deserialize(channel.getUrl(), input);
10
11 byte flag = in.readByte();
12 switch (flag) {
13 //1. 返回结果标记为 Null 值
14 case DubboCodec.RESPONSE_NULL_VALUE:
15 break;
16 case DubboCodec.RESPONSE_VALUE:
17 try {
18 Type[] returnTypes;
19 if (invocation instanceof RpcInvocation) {
20 //2. 读取方法调用返回值类型
21 returnTypes = ((RpcInvocation) invocation).getReturnTypes();
22 } else {
23 returnTypes = RpcUtils.getReturnTypes(invocation);
24 }
25 Object value = null;
26 //3. 如果返回值包含泛型 ,则调用反序列化解析接口
27 if (ArrayUtils.isEmpty(returnTypes)) {
28 // This almost never happens?
29 value = in.readObject();
30 } else if (returnTypes.length == 1) {
31 value = in.readObject((Class?>) returnTypes[0]);
32 } else {
33 value = in.readObject((Class?>) returnTypes[0], returnTypes[1]);
34 }
35 setValue(value);
36 } catch (ClassNotFoundException e) {
37 rethrow(e);
38 }
39 break;
40 case DubboCodec.RESPONSE_WITH_EXCEPTION:
41 try {
42 //4. 保存读取的返回值异常结果
43 setException(in.readThrowable());
44 } catch (ClassNotFoundException e) {
45 rethrow(e);
46 }
47 break;
48 case DubboCodec.RESPONSE_NULL_VALUE_WITH_ATTACHMENTS:
49 try {
50 //5. 读取返回值为Null,并且有请求额外参数
51 addObjectAttachments(in.readAttachments());
52 } catch (ClassNotFoundException e) {
53 rethrow(e);
54 }
55 break;
56 case DubboCodec.RESPONSE_VALUE_WITH_ATTACHMENTS:
57 handleValue(in);
58 handleAttachment(in);
59 break;
60 case DubboCodec.RESPONSE_WITH_EXCEPTION_WITH_ATTACHMENTS:
61 handleException(in);
62 handleAttachment(in);
63 break;
64 default://其他类似请求额外参数的读取
65 throw new IOException("Unknown result flag, expect '0' '1' '2' '3' '4' '5', but received: " + flag);
66 }
67 if (in instanceof Cleanable) {
68 ((Cleanable) in).cleanup();
69 }
70 return this;
71 }在读取服务端响应报文时,先读取状态标志,然后根据状态标志判断后续的数据内容。在上段代码中,响应结果首先会写一个字节标记位。
1.处理标记位代表返回值为Null的场景。
2.代表正常返回,首先判断请求方法的返回值类型,返回值类型方便底层反序列化正确读取,将读取的值存在result字段中。
3.如果返回值包含泛型 ,则调用反序列化解析接口
4.处理服务端返回异常对象的场景, 同时会将结果保存在exception字段中。
5.处理返回值为Null,并且支持服务端请求额外参数透传给客户端,在客户端会继续读取保存在HashMap中的请求额外参数值。
03 总结
本篇是Apache Dubbo 漏洞分析系列的第一篇文章。在这里我们对Dubbo协议和编解码器原理进行了一个简单介绍。在之后的连载中将一步步进行Apache Dubbo 漏洞分析。
绿盟科技 M01N Team 战队
绿盟科技M01N战队专注于Red Team、APT等高级攻击技术、战术及威胁研究,涉及Web安全、终端安全、AD安全、云安全等相关领域。通过研判现网攻击技术发展方向,以攻促防,为风险识别及威胁对抗提供决策支撑,全面提升安全防护能力。
公众号:M01N Team
欢迎扫码关注公众号